近日,中国科学院自动化研究所曾毅研究员课题组提出基于FPGA的脉冲神经网络硬件加速器“智脉·萤火(FireFly)”,并集成了针对FPGA器件特点的DSP运算优化策略和适配脉冲神经网络数据流模式的高效的突触权重和膜电压访存系统,在硬件上实现了脉冲神经网络的推理加速,推动了类脑脉冲神经网络迈向实用化的发展。相关研究成果发表在IEEE Transactions on Very Large Scale Integration (VLSI) Systems上。
随着算法机制不断地深入研究,类脑脉冲神经网络性能逐步提高,但适配脉冲神经网络的硬件仍落后于算法的发展。FPGA作为一种可编程硬件,是新兴的脉冲神经网络的理想硬件载体。然而,现有的针对FPGA的脉冲神经网络加速器在运算和存储效率上都有所不足。
该团队研发的“智脉·萤火”作为具有运算和访存优化的高吞吐率类脑脉冲神经网络加速器,能够有效助力上述问题的解决。为了提升运算效率,该研究充分利用了Xilinx Ultrascale器件中的专用运算模块DSP48E2实现脉冲神经网络的高效运算。为了提升存储效率,该研究设计了一个内存系统实现高效的突触权重和膜电压内存访问。同时,“智脉·萤火”是一个面向边缘型FPGA器件的加速器,在资源受限的FPGA器件上,依旧能达到5.53TOP/s的运算峰值吞吐率。在现有的基于脉动阵列的SNN加速器的研究当中,“智脉·萤火”在运算吞吐率指标上相比起使用同等量级的FPGA器件的研究(如Cerebon[TVLSI'22])有着8.5倍的提升,使其能够在若干深层脉冲神经网络中依旧能达到毫秒级别的延时。作为一个轻量级加速器,“智脉·萤火(FireFly)”与现有的使用大型FPGA设备的脉冲神经网络加速器相比实现了更高的运算效率。
据研发团队介绍,“智脉·萤火”是人工智能平台“类脑认知智能引擎‘智脉’(BrainCog)”在软硬件协同方向上的阶段性成果,为进一步布局未来脉冲神经网络在更为复杂的实际场景中的应用研究奠定了基础。下一步,团队将在硬件上针对FPGA器件优化、微架构设计和稀疏加速等方面持续提升“智脉·萤火”工作性能,并将其实际部署于现实场景中,如基于脉冲神经网络的智能车的自主视觉定位导航,基于事件相机的无人机高速避障,多任务多场景下的机器人环境探索等任务。
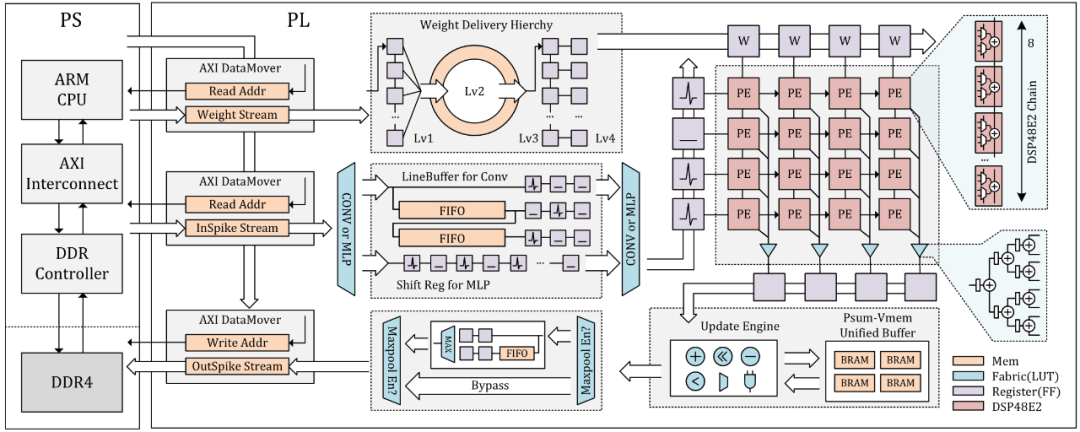
图1 智脉·萤火(FireFly)的整体硬件架构
论文地址:
https://ieeexplore.ieee.org/abstract/document/10143752
内容来源:中国科学院自动化研究所
来源:中国科学院自动化研究所
原文链接:http://www.ia.cas.cn/xwzx/kydt/202307/t20230719_6812823.html
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn







