在数学建模领域,径向基函数网络(Radial basis function network,缩写:RBF network)是一种使用径向基函数作为激活函数的人工神经网络。径向基函数网络的输出是输入的径向基函数和神经元参数的线性组合。1径向基函数网络具有多种用途,包括包括函数近似法、时间序列预测、分类和系统控制,最早由布鲁姆赫德(Broomhead)和洛维(Lowe)在1988年建立。2
径向基函数简介在介绍径向基网络之前,先简单介绍一下径向基函数(Radical Basis Function,RBF)。径向基函数(Radical Basis Function,RBF)方法是Powell在1985年提出的。所谓径向基函数,其实就是某种沿径向对称的标量函数。通常定义为空间中任一点x到某一中心c之间欧氏距离的单调函数,可记作k(||x-c||),其作用往往是局部的,即当x远离c时函数取值很小。例如高斯径向基函数:
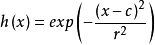
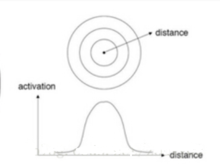 径向基函数的诞生主要是为了解决多变量插值的问题。如图2所示,具体的实现过程是先在每个样本上面放一个基函数,图中每个蓝色的点是一个样本,然后中间图绿色虚线对应的表示的是每个训练样本对应一个高斯函数(高斯函数中心就是样本点)。假设真实的拟合这些训练数据的曲线是蓝色的包络,如果我们有一个新的数据x1,我们想知道它对应的f(x1)是多少,也就是a点的纵坐标是多少。那么由图可以看到,a点的纵坐标等于b点的纵坐标加上c点的纵坐标。而b的纵坐标是第一个样本点的高斯函数的值乘以一个大点权值得到的,c的纵坐标是第二个样本点的高斯函数的值乘以另一个小点的权值得到。而其他样本点的权值全是0,因为我们要插值的点x1在第一和第二个样本点之间,远离其他的样本点,那么插值影响最大的就是离得近的点,离的远的就没什么贡献了。所以x1点的函数值由附近的b和c两个点就可以确定了。拓展到任意的新的x,这些红色的高斯函数乘以一个权值后再在对应的x地方加起来,就可以完美的拟合真实的函数曲线了。
径向基函数的诞生主要是为了解决多变量插值的问题。如图2所示,具体的实现过程是先在每个样本上面放一个基函数,图中每个蓝色的点是一个样本,然后中间图绿色虚线对应的表示的是每个训练样本对应一个高斯函数(高斯函数中心就是样本点)。假设真实的拟合这些训练数据的曲线是蓝色的包络,如果我们有一个新的数据x1,我们想知道它对应的f(x1)是多少,也就是a点的纵坐标是多少。那么由图可以看到,a点的纵坐标等于b点的纵坐标加上c点的纵坐标。而b的纵坐标是第一个样本点的高斯函数的值乘以一个大点权值得到的,c的纵坐标是第二个样本点的高斯函数的值乘以另一个小点的权值得到。而其他样本点的权值全是0,因为我们要插值的点x1在第一和第二个样本点之间,远离其他的样本点,那么插值影响最大的就是离得近的点,离的远的就没什么贡献了。所以x1点的函数值由附近的b和c两个点就可以确定了。拓展到任意的新的x,这些红色的高斯函数乘以一个权值后再在对应的x地方加起来,就可以完美的拟合真实的函数曲线了。

具体参见:径向基函数
径向基网络简介到了1988年, Moody和 Darken提出了一种神经网络结构,即RBF神经网络,属于前向神经网络类型,它能够以任意精度逼近任意连续函数,特别适合于解决分类问题。
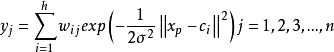
RBF网络的结构与多层前向网络类似,它是一种三层前向网络。输入层由信号源结点组成;第二层为隐含层,隐单元数视所描述问题的需要而定,隐单元的变换函数是RBF径向基函数,它是对中心点径向对称且衰减的非负非线性函数;第三层为输出层,它对输入模式的作用作出响应。从输人空间到隐含层空间的变换是非线性的,而从隐含层空间到输出层空间变换是线性的。2
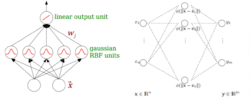
RBF网络的基本思想是:用RBF作为隐单元的“基”构成隐含层空间,这样就可将输入矢量直接(即不需要通过权连接)映射到隐空间。根据Cover定理,低维空间不可分的数据到了高维空间会更有可能变得可分。换句话来说,RBF网络的隐层的功能就是将低维空间的输入通过非线性函数映射到一个高维空间。然后再在这个高维空间进行曲线的拟合。它等价于在一个隐含的高维空间寻找一个能最佳拟合训练数据的表面。这点与普通的多层感知机MLP是不同的。3
当RBF的中心点确定以后,这种映射关系也就确定了。而隐含层空间到输出空间的映射是线性的,即网络的输出是隐单元输出的线性加权和,此处的权即为网络可调参数。由此可见,从总体上看,网络由输人到输出的映射是非线性的,而网络输出对可调参数而言却又是线性的。这样网络的权就可由线性方程组直接解出,从而大大加快学习速度并避免局部极小问题。
从另一个方面也可以这样理解,多层感知器(包括BP神经网络)的隐节点基函数采用线性函数,激活函数则采用Sigmoid函数或硬极限函数。而RBF网络的隐节点的基函数采用距离函数(如欧氏距离),并使用径向基函数(如Gaussian函数)作为激活函数。径向基函数关于n维空间的一个中心点具有径向对称性,而且神经元的输入离该中心点越远,神经元的激活程度就越低。隐节点的这一特性常被称为“局部特性”。4
RBF网络的设计与求解RBF的设计主要包括两个方面,一个是结构设计,也就是说隐藏层含有几个节点合适。另一个就是参数设计,也就是对网络各参数进行求解。1由上面的输入到输出的网络映射函数公式可以看到,网络的参数主要包括三种:径向基函数的中心、方差和隐含层到输出层的权值。到目前为止,出现了很多求解这三种参数的方法,主要可以分为以下两大类:
结构设计通过非监督方法得到径向基函数的中心和方差,通过监督方法(最小均方误差)得到隐含层到输出层的权值。具体如下:
(1)在训练样本集中随机选择h个样本作为h个径向基函数的中心。更好的方法是通过聚类,例如K-means聚类得到h个聚类中心,将这些聚类中心当成径向基函数的h个中心。
(2)RBF神经网络的基函数为高斯函数时,方差可由下式求解:
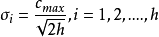 式中cmax 为所选取中心之间的最大距离,h是隐层节点的个数。扩展常数这么计算是为了避免径向基函数太尖或太平。
式中cmax 为所选取中心之间的最大距离,h是隐层节点的个数。扩展常数这么计算是为了避免径向基函数太尖或太平。
(3)隐含层至输出层之间神经元的连接权值可以用最小均方误差LMS直接计算得到,计算公式如下:(计算伪逆)(d是我们期待的输出值)
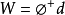
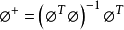
参数设计采用监督学习算法对网络所有的参数(径向基函数的中心、方差和隐含层到输出层的权值)进行训练。主要是对代价函数(均方误差)进行梯度下降,然后修正每个参数。具体如下:
(1)随机初始化径向基函数的中心、方差和隐含层到输出层的权值。当然了,也可以选用结构设计中的(1)来初始化径向基函数的中心。
(2)通过梯度下降来对网络中的三种参数都进行监督训练优化。代价函数是网络输出和期望输出的均方误差:
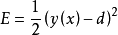 然后每次迭代,在误差梯度的负方向已一定的学习率调整参数。
然后每次迭代,在误差梯度的负方向已一定的学习率调整参数。
本词条内容贡献者为:
王伟 - 副教授 - 上海交通大学