 大数据文摘出品来源:OpenAI编译:牛婉杨、刘俊寰
大数据文摘出品来源:OpenAI编译:牛婉杨、刘俊寰
GPT-3的热度还在发酵,OpenAI又放了个大招。这次的研究往图像界迈出了新的一步。
刚刚,OpenAI发布了一篇博客文章,介绍了将GPT应用到图像领域的研究进展,并且发现,在图像领域,GPT-2仍然可以工作,并且性能良好。
研究人员发现,就像利用大型transformer模型训练语言一样,用同样的模型训练像素序列,可以生成连贯的图像像素样本。通过建立样本质量和图像分类精度之间的相关性,OpenAI表明,他们的最佳生成模型也包含了在无监督环境下与顶层卷积网对抗的特征。
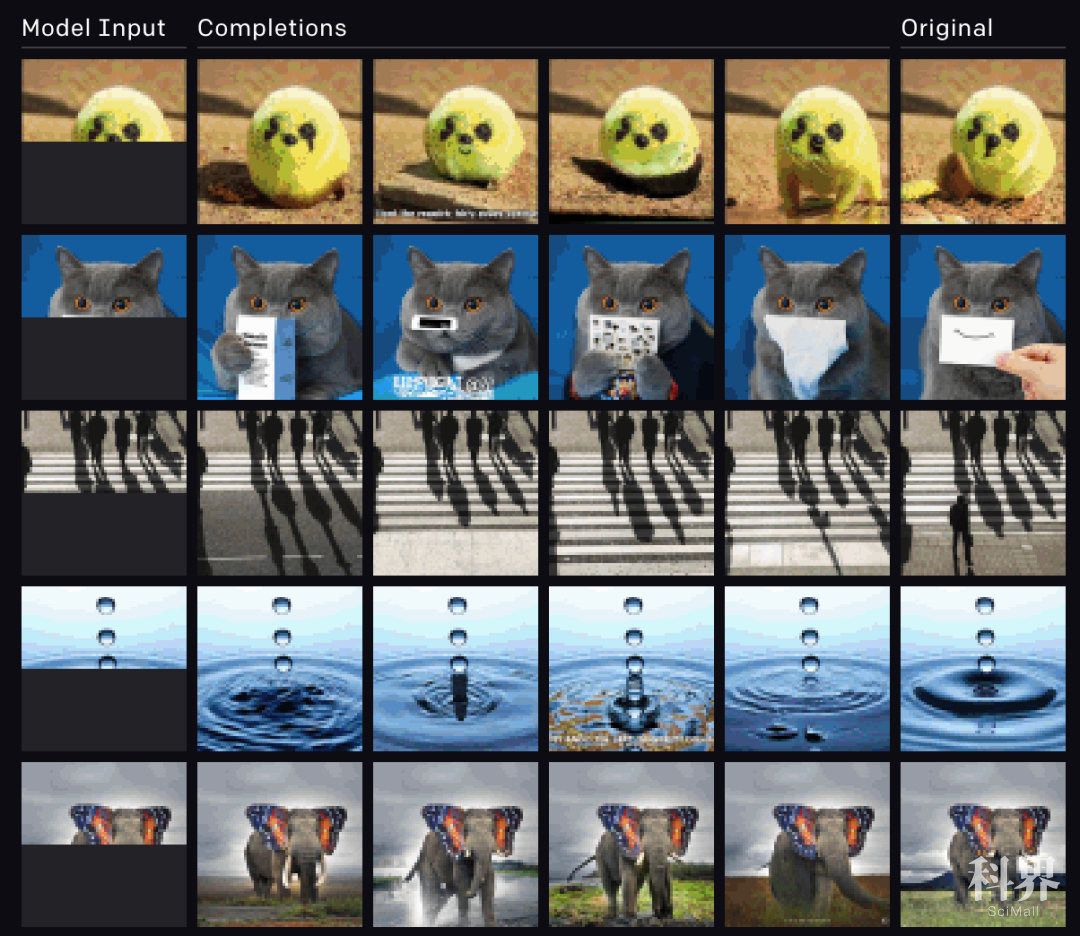
第一列为研究人员为模型提供的半张图片,中间是模型自动补全的完整图像,最后一列是原始图像
我们都知道,对于机器学习来说,无监督学习或没有人为标签的数据学习长期以来都是一项不小的挑战。最近,在语言上,机器学习已经取得了一些值得称赞的成就,如BERT、GPT-2、RoBERTa、T5等,但是,这类模型尚未成功产生用于图像分类的功能。
不过,也正是由于BERT和GPT-2这类模型与领域无关,它们可以直接应用于任何形式的一维序列。比如在图像领域,当在展开为长像素序列的图像上训练GPT-2时,研究人员就发现,该模型似乎可以理解二维图像特征,例如外观和类别。即使在没有人工提供标签的指导下,生成的相干图像样本的范围也足以证明。同时,该模型的功能可以在许多分类数据集上实现最新性能,也就是说,具有最新的无监督准确性。
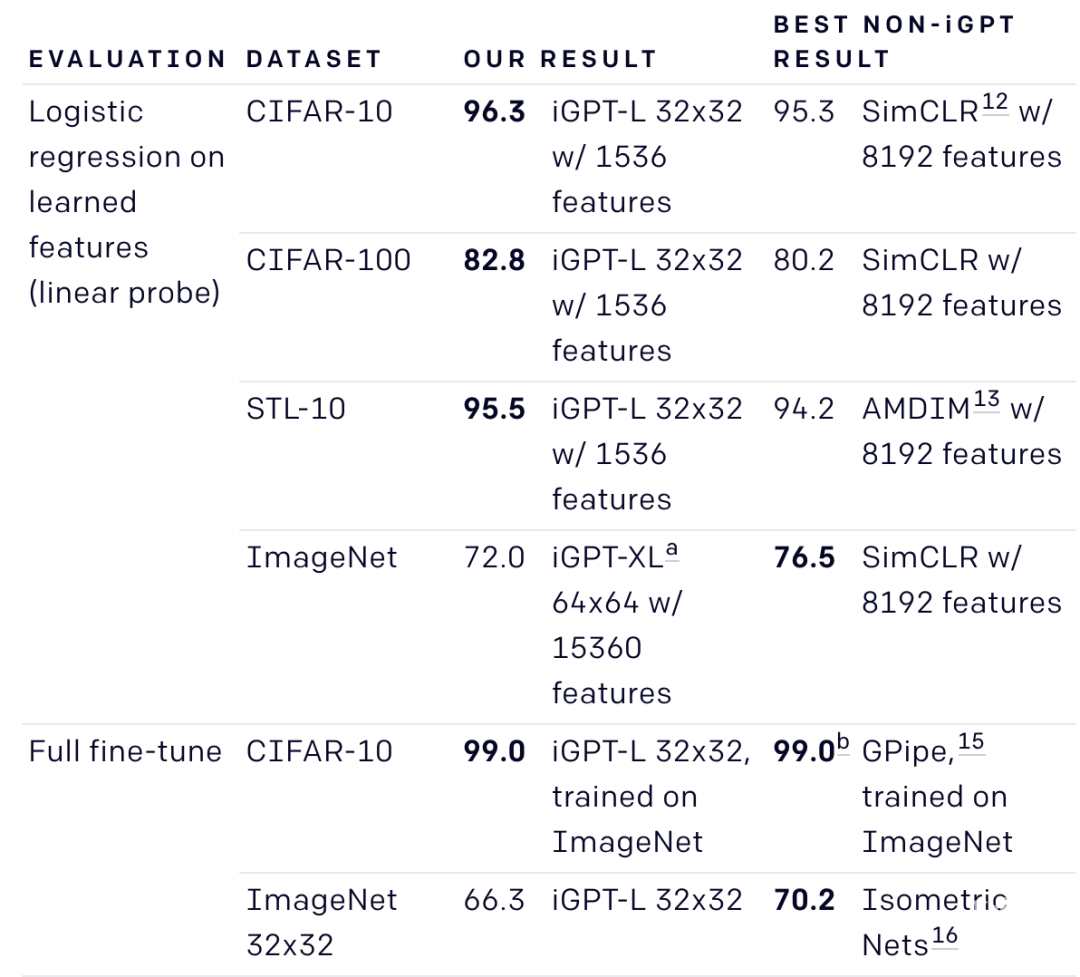

为了突出生成序列模型作为通用无监督学习算法的潜力,OpenAI故意在语言上使用与GPT-2相同的transformer架构。研究人员也就需要更多的计算产生与顶级无监督卷积网络相竞争的特性,结果表明,当面对一个正确的模型先验未知的新领域时,GPT-2可以学习优秀的特性,而不需要特定领域的架构设计选择。
在语言方面,依赖于单词预测的无监督学习算法(如GPT-2和BERT)非常成功,在大量的语言任务中表现最佳。这种成功的一个可能原因是下游语言任务的例子在文本中很自然地出现:问题后面经常跟着答案,段落后面经常跟着总结。相反,像素序列没有明确包含其所属图像的标签。
即使没有这种明确的监督,图像上的GPT-2仍然可以工作的原因是:一个足够大的变压器训练下一个像素预测可能最终学会生成不同的样本与清晰可识别的对象。一旦它学会了这样做,被称为“综合分析”的想法表明,模型也将知道对象类别。许多早期的生成模型都是受到这个想法的推动,最近BigBiGAN就是一个产生令人鼓舞的样本和特征的例子。在我们的工作中,我们首先展示了更好的生成模型实现更强的分类性能。然后,通过优化GPT-2的生成能力,研究人员发现在很多场景下都达到了顶级的分类性能,为综合分析提供了进一步的证据。
这项研究表明,通过权衡二维知识交换规模,从网络中间选择预测特征,序列转换器就可以与顶级卷积网络竞争无监督图像分类。值得注意的是,GPT-2语言模型直接应用于图像生成就足以实现实验结果。
来源:大数据文摘
来源:BigDataDigest 大数据文摘
原文链接:http://mp.weixin.qq.com/s?__biz=MjM5MTQzNzU2NA==&mid=2651682169&idx=4&sn=fbe7ff487a7617733783df65b9dd5505&chksm=bd4c52ea8a3bdbfc357f1a481d35613f1533aecd8c5e6e93f3526466f4b04a34b5bf0a8ce9d5&scene=27#wechat_redirect
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn


