来源:PaperWeekly
预训练语言模型语言模型(Language Modeling)作为自然语言领域经典的序列建模任务,已有数十年的研究历史。
近年来,因其自监督的特性备受学术界与工业界关注,相继涌现出 GPT2、BERT、RoBERTa、XLNET 等一系列预训练语言模型,不断刷新自然语言各类任务榜单。预训练+微调模式已然成为自然语言处理领域的新范式。
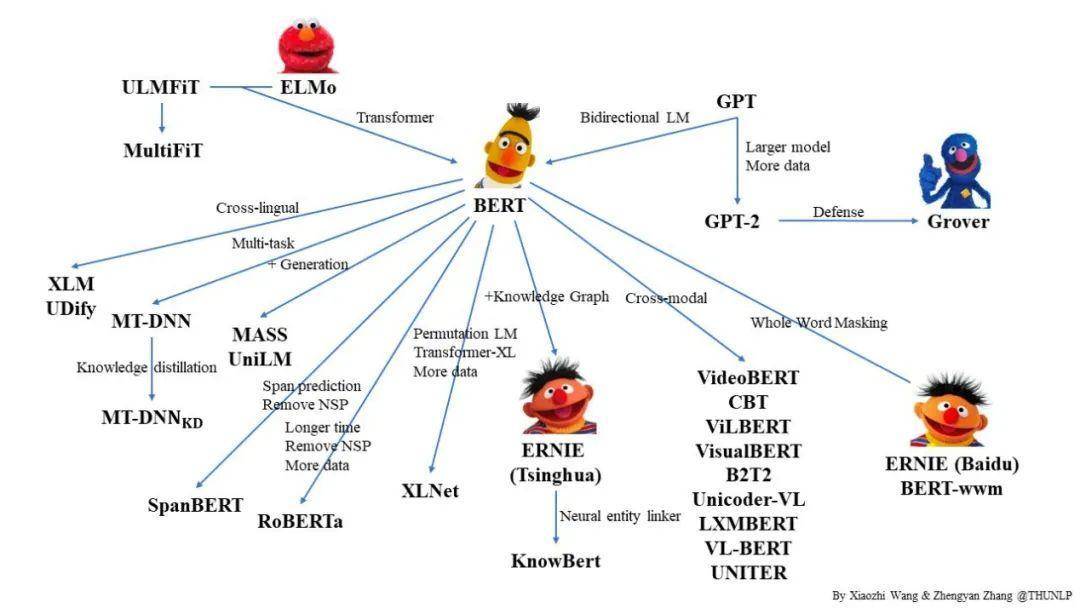
有趣的是,这些不断刷新各类排名榜单的预训练模型无一例外都采用了Transformer(Vaswani et al., 2017)架构。该架构自 2017 年提出以来风靡自然语言领域,因其高效的自注意力机制,逐步替代传统的循环神经网络。
为了编码输入序列中词语之间的位置关系,Transformer 需要给每个输入 token 构建一个位置向量。每个位置向量表达了当前 token 在输入序列中的位置,模型通过海量的输入数据,来学习这些位置向量之间的关系。
然而,Transformer 的提出时,主要针对的是机器翻译等输入序列较短的自然语言任务(从 1~512 个词不等),而预训练语言模型的文本序列通常是篇章级别的长度(从 512~1024 个词不等)。
对于这种较长的自然语言序列而言,原始的 Transformer 的位置向量很难学习到显著的位置关系。
比如第 3 位和第 123 位的两个 token,可能是出现在同一个文章段落,并且是相邻的两个句子中的两个词;也可能是同一个文章段落,但非相邻的句子中的两个词;甚至是同一文章不同段落的两个词。
因此,仅仅指出两个词在整个输入文本序列中的位置,不足以表达它们在文本作者的篇章结构中的位置关系。
该文章中提出的 SegaBERT 模型,在 Transformer 原始位置向量的基础上,对段落、句子、词语三者间的位置关系联合建模,更符合语言逻辑习惯,也更益于模型学习。它使得 Transformer 结构对输入序列的分隔信息有了更好的建模能力,以此获得更好的文本编码表示,用以提升下游自然语言处理任务。
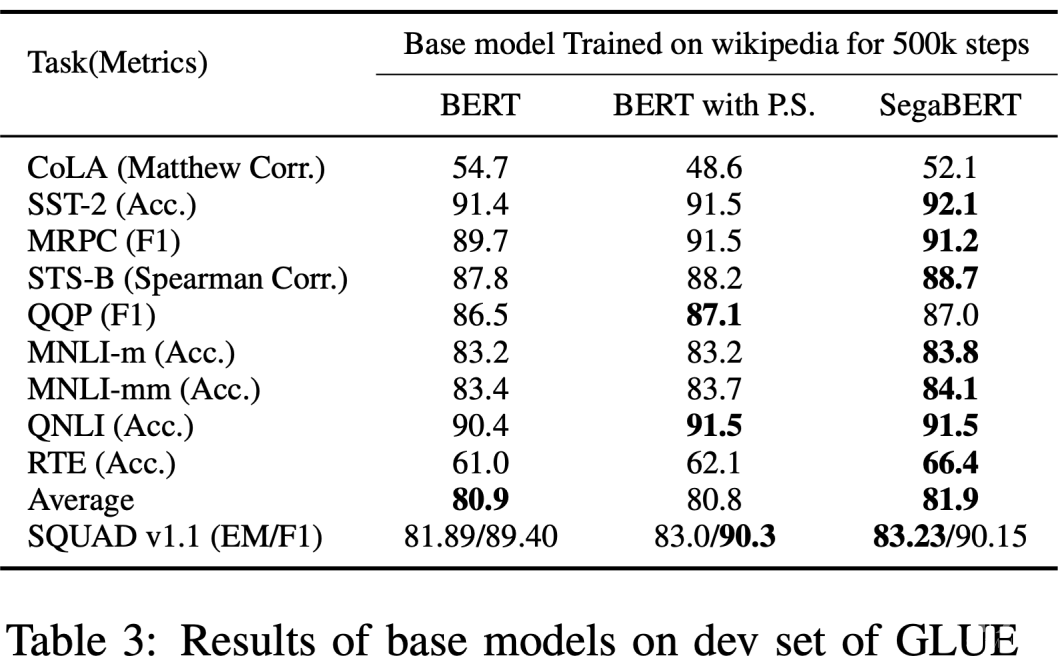
为了验证这种结构改进自身带来的功效,SegaBERT 模型使用了与 BERT 相同的训练配置,在人类自然语言理解任务 GLUE 的七项任务中全面超越 BERT,整体平均分数提升 1.2 个点。
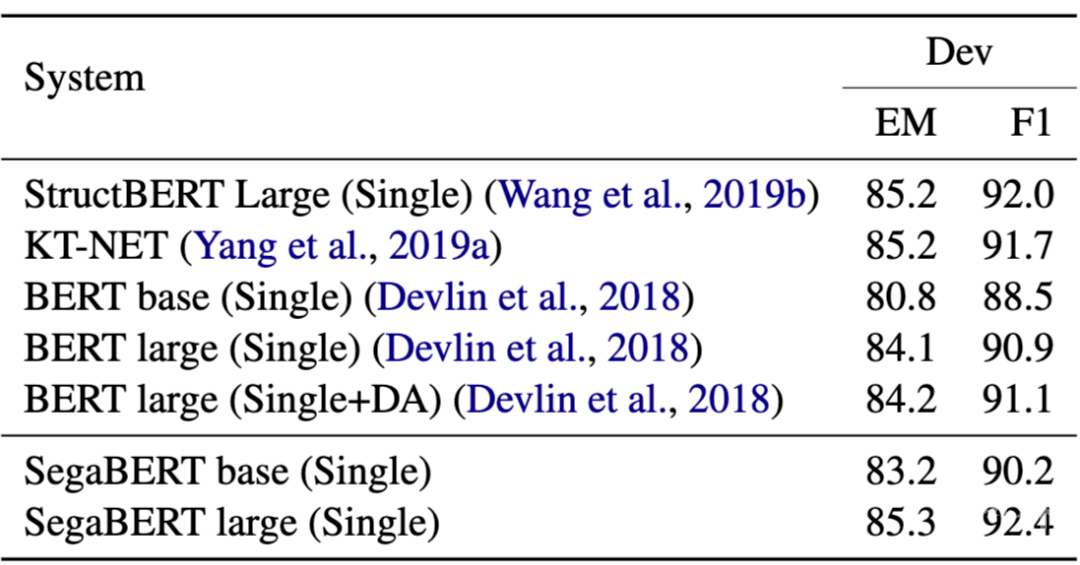
同时,SegaBERT 也在斯坦福大学的阅读理解任务 SQUAD 中的 EM score 和 F1 score 两项指标上分别提升 1.2 和 1.5 个点。
论文介绍
和 BERT 相比,SegaBERT 为每个输入的词/子词构建其段落索引、句子索引和词索引,同时在模型中设置段落位置向量、句子位置向量和词位置向量。通过位置索引和位置向量为模型输入序列提供位置向量表示,如图 2 所示:
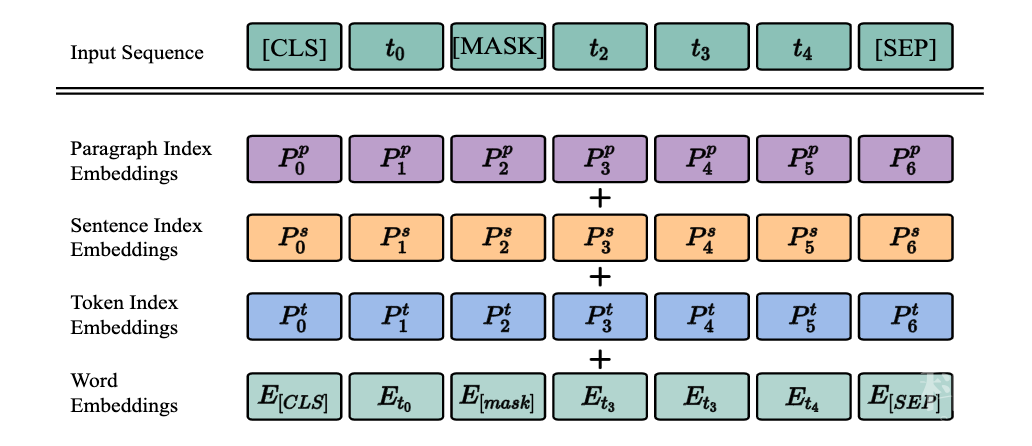 ▲图2. 模型输入
▲图2. 模型输入相比 BERT 中使用 512 个词位置索引对输入序列中每个词进行位置标示,SegaBERT 采用 50 个段落位置索引、100 个句子位置索引和 256 个词位置索引,为输入序列中的每个词标示其三重位置信息。
即为每个词赋予一个三元组位置向量,分别包含其所在段落位置索引、所在句子在相应段落中的位置索引及该词在其所在句子内的位置索引。这样,SegaBERT 在进行文本编码时,能够做到片段感知(segment-aware),捕捉到更丰富的篇章结构信息。
因此,SegaBERT 在预训练阶段,能利用更丰富的位置表征,学习到信息更丰富的上下文表示。这样的改进,提升了预训练语言模型的文本编码能力,使其在微调阶段得到更完善的句子/篇章表示,进而提升下游任务的预测效果。
通过使用 Tesla V100 16 卡机,SegaBERT 预训练了 SegaBERT-base 模型和 SegaBERT-large 模型,分别采用 12 层 Transformer、768 维隐层表示、12 个多头注意力与 24 层 Transformer、1024 维隐层表示、24 个多头注意力。
其中,SegaBERT-base 模型只使用了 wikipedia 数据(12GB)进行训练,训练步数为 500K;而 SegaBERT-large 模型则使用了 wikibooks 数据(16GB),训练步数为 1M。
在训练任务上,SegaBERT 采用了和 BERT 相同的 MLM(掩码语言模型)任务,即对输入的 512 个 token 进行随机掩码。通过模型训练,对这些被掩码的位置进行预测,还原其原本的文本内容。值得注意的是,SegaBERT 并没有引入其他辅助任务,例如 NSP(下句预测)等。
实验结果
SegaBERT 采用同 BERT 相同的参数量、预训练数据与训练超参与进行语言模型预训练。其 Large 模型在人类自然语言理解任务 GLUE 中,七项任务超越 BERT,整体平均分数提升 1.2 个点。除此之外,在斯坦福大学的阅读理解任务 SQUAD 中,SegaBERT 更是在 F1 score 和 EM score 上分别提升 1.2 和 1.5 个点,更是超越 KT-NET(基于 BERT 进行融合外部知识库的微调模型)、StructBERT(多种辅助任务参与预训练的改进版 BERT)和 BERT_DA(利用数据增广进行微调的 BERT)。
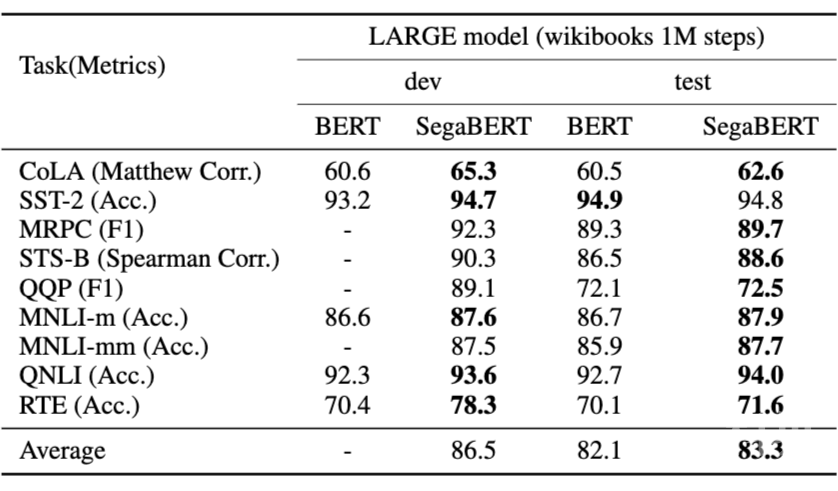
同时,为了说明添加的段落位置表示和句子位置表示的有效性,该文章还进行了在 BERT 原本的 512 个词位置索引的基础上,添加 50 个段落位置索引和 128 个句子位置索引的对比实验(对应下表中的实验组第二列 BERT with P.S.)。
这里需要说明的是,BERT 中的词位置索引是该词在整个输入的长度为 512 的序列中的绝对位置,而 SegaBERT 中词位置索引是该词在其所在句子中的相对位置。
可以看到,该组实验在除 CoLA 外的其余 7 项 GLUE 任务和阅读理解 SQUAD 任务相比于原始的 BERT 均有明显的提升,其中 SQUAD 任务的结果与 SegaBERT 相近。
这组实验表明,简单的段落和句子的位置表征引入,就能起到提升预训练语言模型的效果。
在 Transformer 和预训练语言模型成为 NLP 标准范式的今天,SegaBERT 通过重新定义 Transformer 底层输入的位置表征,在与 BERT 采用相同的预训练数据、计算资源与模型规模条件下,取得了较为明显的提升效果。
值得注意的是,这种新的位置表征方法并非仅限于改进 BERT,而是可以推广且应用到所有利用 Transformer 结构进行预训练语言模型的工作中。可以预见的是,作为第一篇研究 Transformer 输入片段多层次位置表征的论文,其位置表征问题会逐步成为预训练语言模型与 Transformer 结构的未来研究方向。
来源:paperweekly PaperWeekly
原文链接:https://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw==&mid=2247506432&idx=2&sn=7f4f2e858920461ead31aa2f736e69c7&chksm=96ea0580a19d8c96106bb2aa439cda885e9529fba7b01ffe720ffd9e256a22c873e743d82336#rd
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn


